ビデオキャプチャから画像を取得して文字認識(OCR)させる方法を以前はTesseractを使用して紹介したのですが、今度はWindows10の機能にあるOCRを使ってやってみたのでサンプルコードを載せておきます。
Tessaract版の解説はこちらにあります。
サンプルプログラム
https://github.com/kame-chan/WPF/tree/master/Win10OCR
Tessaract版で紹介したコードに手を加えたものなので解説は少なめで。
プログラム概要
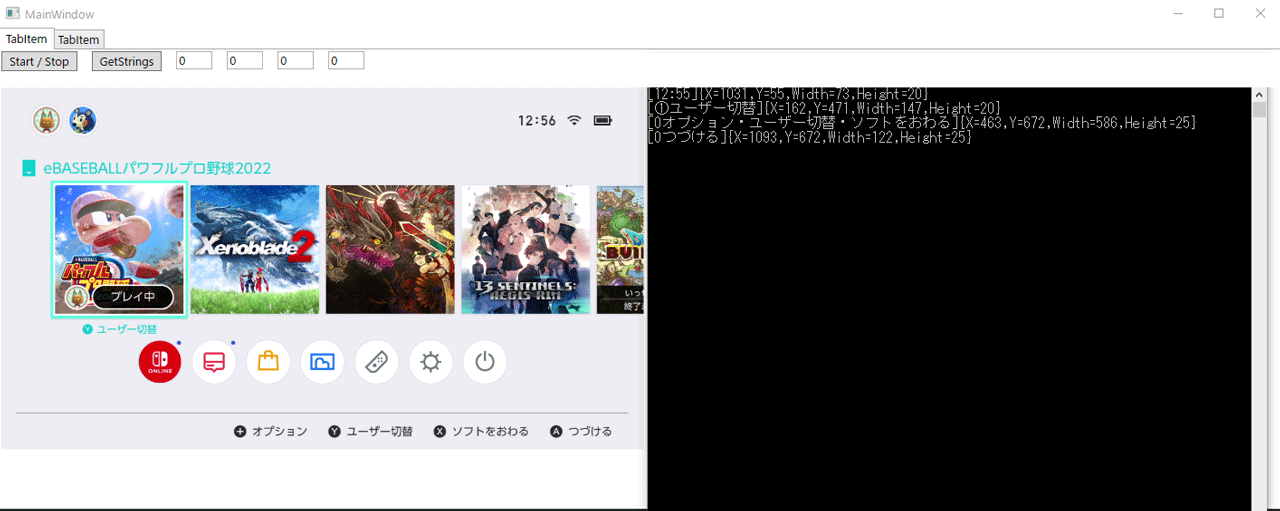
- OpenCvSharp4でビデオキャプチャがら画像取得
- MatをImageSourceに変換
- ImageSourceをSoftwareBitmapに変換
- OcrEngineで画像を認識
学習機能はありませんがTessaractよりも精度が高いです。こちらも通信なしの無料で使えるのでTessaractよりも良いかもしれません。
Nuget

- Microsoft.Windows.SDK.Contracts 10.0.22000.196
- OpenCvSharp4 4.5.5.20211231
- OpenCvSharp4.runtime.win 4.5.5.20211231
- OpenCvSharp4.WpfExtensions 4.5.1.20201229
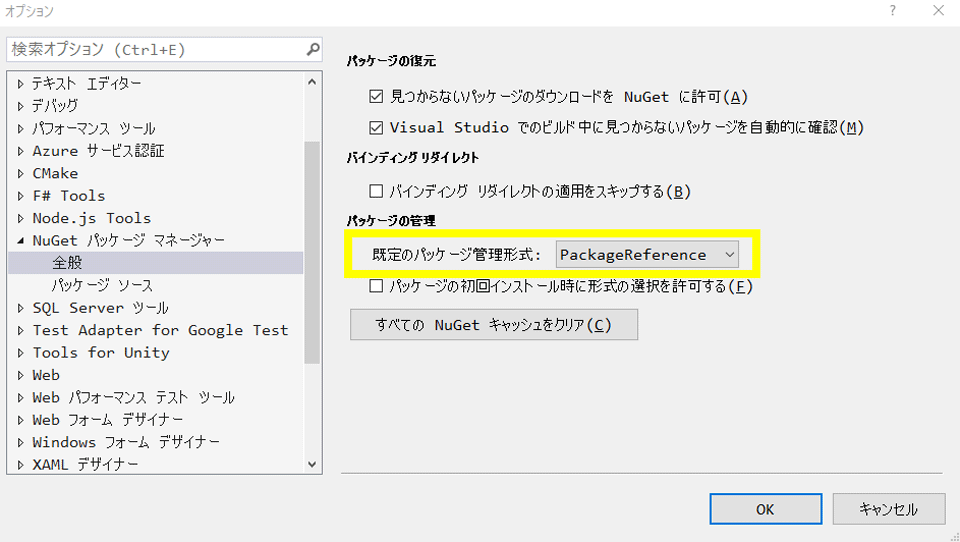
パッケージの管理はPackageReferenceにしておきましょう。パッケージ競合でOCRが使えないこともあるので、上手くいかないときはMicrosoft.Windows.SDK.Contractsだけにして最小構成で調べましょう。
OcrResultから位置を取る(X,Y,Width,Height)
解析結果のOcrResultオブジェクトには行>文字という形で入っていて、位置は1文字単位で格納されています。
各行の最初の文字と最後の文字から全体の配置を取得しましょう。
OcrResult result = await RunOcr(sbitmap);
Console.WriteLine(result.Text);
string output = "";
foreach (var line in result.Lines)
{
// 1行分の文字列を格納するためのバッファ
var sb = new System.Text.StringBuilder();
// 出現場所は各文字ごとに記録されている
RectangleF cloneRect = new RectangleF(
(float)line.Words[0].BoundingRect.Left,
(float)line.Words[0].BoundingRect.Top,
(float)(line.Words[line.Words.Count - 1].BoundingRect.Right - line.Words[0].BoundingRect.Left),
(float)(line.Words[0].BoundingRect.Bottom - line.Words[0].BoundingRect.Top)
);
foreach (var word in line.Words)
{
// wordには1文字ずつ入っているので結合
sb.Append(word.Text);
}
output += string.Format("[{0}]{1}{2}",
sb.ToString().TrimEnd(),
cloneRect,
Environment.NewLine // 改行
);
}
Console.WriteLine(output);
ということで以上です。なかなかの精度で日本語にも対応していますが、記号やアイコンが混ざるゲーム画面だとまだ少し辛いですね。
Tessaractに学習させてもっと精度を上げることができたらまた紹介しようと思います。