

OCRの技術を使ってゲーム画面に表示される文字をデータとして取り込むツールを作ったので紹介します。技術的な解説のみで配布などはありません。
OCRとは
OCR(Optical Character Recognition:光学文字認識)のことで、手書きや印刷された画像やPC上の画像に書かれている文字を、テキストデータに変換する技術のこと。
過去にも何度か書いているのでまたかと思われた方も居られるかもしれませんが、今回は2026年版として精度が大幅に向上したので新たに解説しておきます。
過去記事
などなど。
これまでに使用した文字認識、画像認識
これまでに使ったのはTesseractとWindows10のWindowsMediaOcrです。
あとは精度を限りなく高めるためにあらかじめ用意した画像と比較するテンプレートマッチも使用したことがあります。
確率調査や自動化プログラムを組む場合ならテンプレートマッチを採用しましょう。
Tesseractはローカルで動く単独のAPIですが、2021年時点でv5のものを使用したときは日本語の文字を読ませるにはまだ精度が足りないという感じでした。
WindowsMediaOcrも2022年に使ってまずまずの精度だったので今回も試してみたのですが、小さいひらがなや濁点に弱く、日本語モデルを使用するとローマ字や数字に弱くなってしまうという欠点がありました。
あとは最近の流行りとして「PaddleOCR」が良いぞ、ということで使ってみたのですが、これもゲーム画面に含まれる日本語に対しては精度が低く使えませんでした。
どうしたものかと調べていたところ、最後に出てきたのがWindows11の「SnippingTool OCR」です。(oneocr)
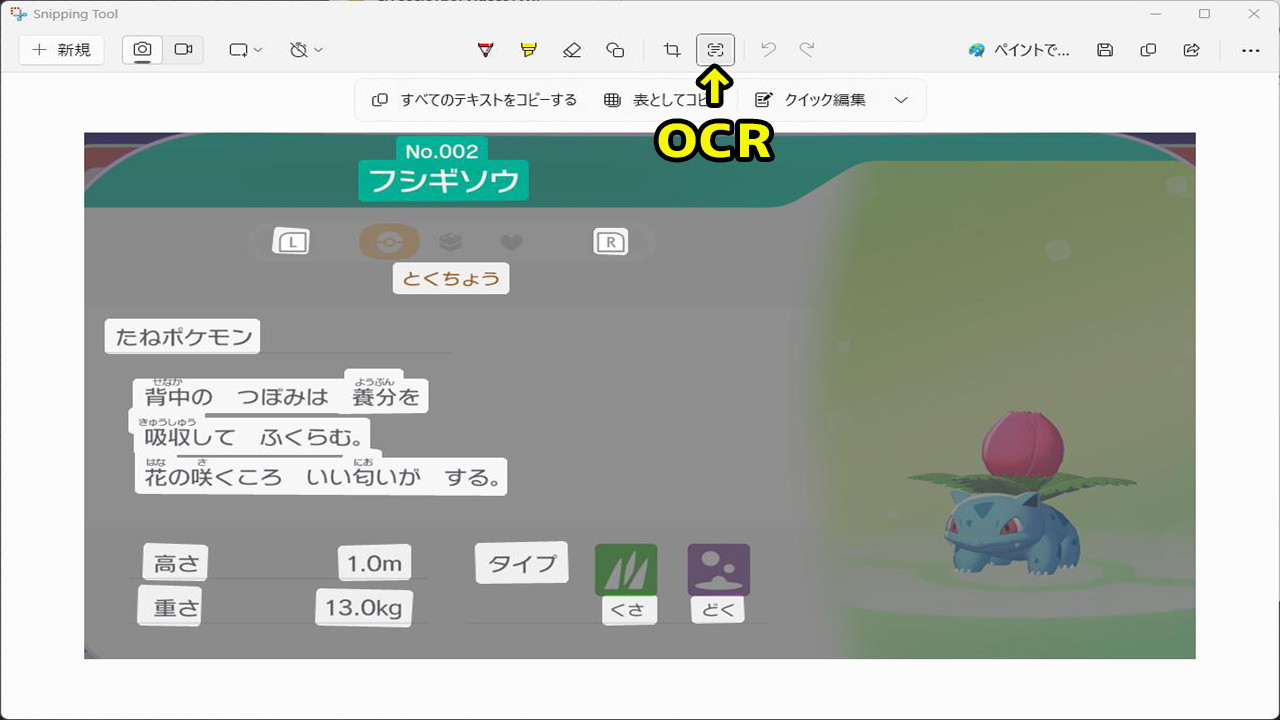
「SnippingTool」はWindows11に標準で入っているスクリーンショットツールで、削除していなければAlt+Shift+Sで使えます。切り取る範囲を指定したら右下に通知が出るのでクリックすると画像のようなツールが開きます。
上の真ん中辺りにあるボタンを押すとOCRで文字を読み取ってくれます。
テキストとしてコピーしたり、表形式でコピーしてくれるスグレモノ。Windows本体のサービス関連は余計な物が多いですが、細かなツールには光るものもありますね。
今回実際に取れたテキストはこれです。
「No.002 フシギソウ L R とくちょう ようぶん 養分を はな たねポケモン 背中の つぽぼみは きゆうしゅう 吸収して ふくらむ。 にお 花の咲くころ いい匂いが する。 高さ 重さ 1.0m 13.0kg タイプ くさ どく」
範囲指定をしていないので余計なものが混ざったり、ルビの大文字小文字が曖昧だったりしますが濁点に強いのは素晴らしいです。
で、このSnipping Toolで使われているOCRの技術は公式にAPI化されていないので普通は使えないのですが、非公式に処理を扱えるようにしたラッパーがあります。
今回はこれらを使い、C#のWinUI3でソフトを作りました。(記事のタグはWPFのままです)
ビデオキャプチャの方は「OpenCvSharp」で取り込んでいるだけなので省略します。
Snipping Toolを使うには
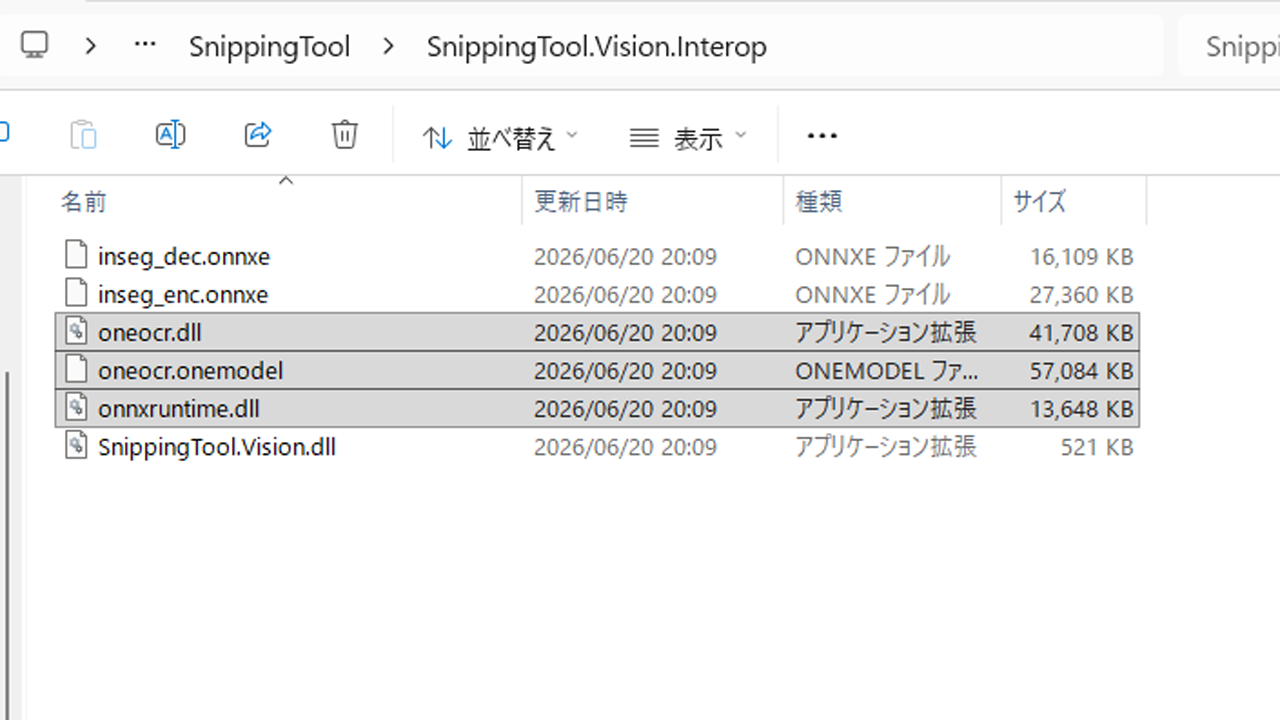
今回はC#なのでksasaoさんが公開されているラッパーを自分でビルドして使います。
使用するにはビルドした「SnippingToolOcr.dll」以外にも
C:\Program Files\
WindowsApps\Microsoft.ScreenSketch_11.2602.49.0_x64__***\
SnippingTool\SnippingTool.Vision.Interop
にあるoneocr.dll、oneocr.onemodel、onnxruntime.dllの3つが必要になります。
これらは自分のPCからコピーしてくる必要があります。元のパスだと権限エラーになったりします。自分のプロジェクトの.exeファイルが作成される場所に配置しましょう。
将来的にはSnippingToolの更新により利用できなくなることも考えられるので、バージョンを整えましょう。
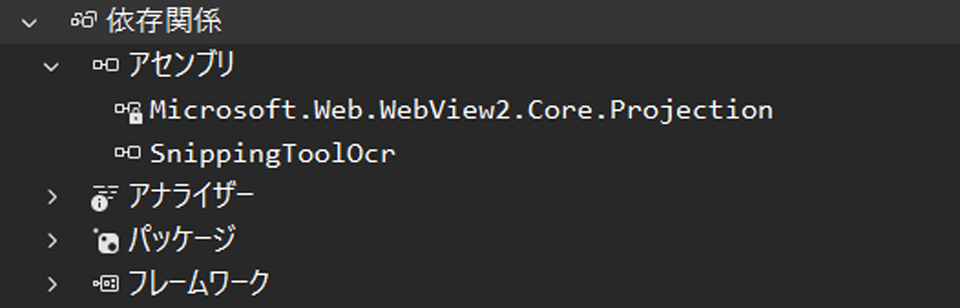
SnippingToolOcr.dllはどこでもよいですが、依存関係に参照を追加しておきましょう。
using SnippingToolOcr;も追加。
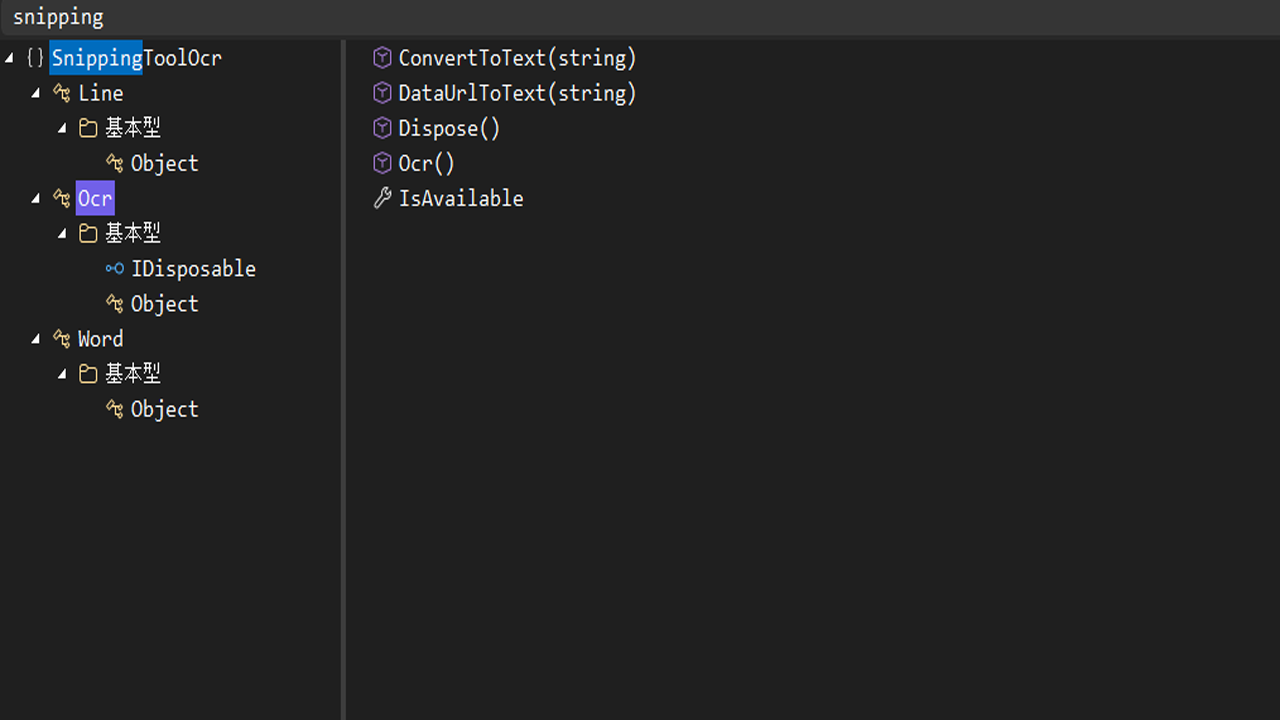
参照が追加できたら表示>オブジェクトブラウザーから「snipping」で絞るとコマンドを確認できるようになります。
最初はnew SnippingToolOcr.Ocr()でインスタンスを作って、Ocr.IsAvailable()で使える状態になっているか確認すると良いでしょう。
Snipping ToolでOCRの精度を高めつつ、高速かつメモリを抑えるには

Snipping Tool OCRは精度は高いですが、私の環境で1回辺りの処理に600msほどの時間が掛かっていたので、精度を保ちつつ速度を上げるには工夫が必要でした。
まず単純に画面全体を渡すと不要な文字まで返ってきてしまうので、必要な範囲だけ指定して画像を渡す必要があります。
ゲームのUIはほぼ固定されているのでクリッピング処理はかなり理にかなっています。
しかし必要な部分だけ切り取って解析させてを繰り返すと、呼び出す回数分だけ処理時間が増えてしまいます。
なのでスマートな方法としてクリッピングした部分は縦に連結させるのがポイントです。
さらにこのときに最大横幅に合わせて黒塗りで潰すとなお良いです。
さらにさらに結合時に十分な余白も追加することでShippingToolOcr.Lineから返ってくる座標のグループ化もしやすくなります。
速度と精度についてはこれでかなり改善します。日本語の無料(非公式)のローカルOCRとしては現時点でベストパフォーマンスかもしれません。
実際の速度と精度についてのサンプルはツイッターに動画を上げておきました。
メモリの消費を抑えるには
私は30fpsでTaskに処理させていたのですがどうもShippingToolOcrの処理でメモリリークが起こっているようで、固まる寸前までメモリが増え続けていました。(若干速度にも影響)
最終的には修正出来たのでプルリクエストを投げた方が喜ばれるのかもしれませんが、非公式の扱いなので原因と修正だけ書いておきます。
原因
公開されている(d8cbb21)ではOcr.csのRunOcr()が、OCRを実行するたびにCreateOcrPipeline(モデルのロード)とCreateOcrProcessOptionsを毎回新規作成しているのですが、そのあとで一度も解放していません。
またRunOcrPipelineが返すOCRの結果(インスタンス)も解放されていません。
oneocr.dllにはこれらを解放するReleaseOcrPipeline、ReleaseOcrProcessOptions、ReleaseOcrResult、ReleaseOcrInitOptionsがありますが、NativeMethods.csにバインドされていない状態でした。
修正
まずNativeMethods.csにバインドを追加。
[DllImport("oneocr.dll", CallingConvention = CallingConvention.Cdecl)]
public static extern void ReleaseOcrResult(long instance);
[DllImport("oneocr.dll", CallingConvention = CallingConvention.Cdecl)]
public static extern void ReleaseOcrInitOptions(long ctx);
[DllImport("oneocr.dll", CallingConvention = CallingConvention.Cdecl)]
public static extern void ReleaseOcrPipeline(long pipeline);
[DllImport("oneocr.dll", CallingConvention = CallingConvention.Cdecl)]
public static extern void ReleaseOcrProcessOptions(long opt);
Ocr.csも修正、pipelineとprocessOptionsは初回のInitialize()で1回だけ作成して、以降は使い回すようにしましょう。
OCR結果(インスタンス)も使用後にReleaseOcrResultで解放。
NativeMethods.ReleaseOcrResult(instance);
OcrクラスをIDisposableにし、終了時にpipeline/processOptions/initOptionsを解放。
WinUI3で作って映像無しで90MB、映像ありで300MB、OCR常駐で600MBほどです。
ということで以上です。これでファイルを直接見れないゲームのデータ作りにも対応できそうです。しかしどうやってもOCRの精度は100%にはならないので、誤字脱字は増えると思います。無いよりはマシとして大目に見てやってください。コピペすると出どころがすぐに分かるのはプラスですかね。

国立国会図書館が出したOCR改良で結構おすすめです
https://lab.ndl.go.jp/news/2025/2026-02-24/