
「ゼノブレイドDE 宝箱のドロップ率について」で書いた、文字認識を使って自動でアイテムのドロップ率を集計する方法について。
入力制御のプログラムを書く方法よりもう少し手軽な方法を考えたので紹介します。
今回紹介するやり方はマクロコントローラー(Gulikit Kingkong Pro Controller)を使用します。マクロコンの詳細については過去記事があるのでこちらを確認してください。
Switch用のマクロコントローラー「Gulikit Kingkong Pro Controller」を購入したのでレビュー評価
大まかな流れ
- マクロ機能があるコントローラーを使用してドロップ画面をキャプチャ
- キャプチャ画像が必要枚数集まったら「XnConvert」で必要部分だけ切り抜き
- 「Tesseract」を使用してテキスト出力
- 出力されたテキストを読みやすく整形
マクロコンを使って画面をキャプチャ(保存)することでそれ専用の処理を書く必要がなくなりました。
これでキャプチャボードやマイコンを必要とせず、PCと最低限のスキルがあればドロップ率などの検証ができますね!
ではもう少し詳しく解説していきます。
マクロコンを使って自動で画面キャプチャする
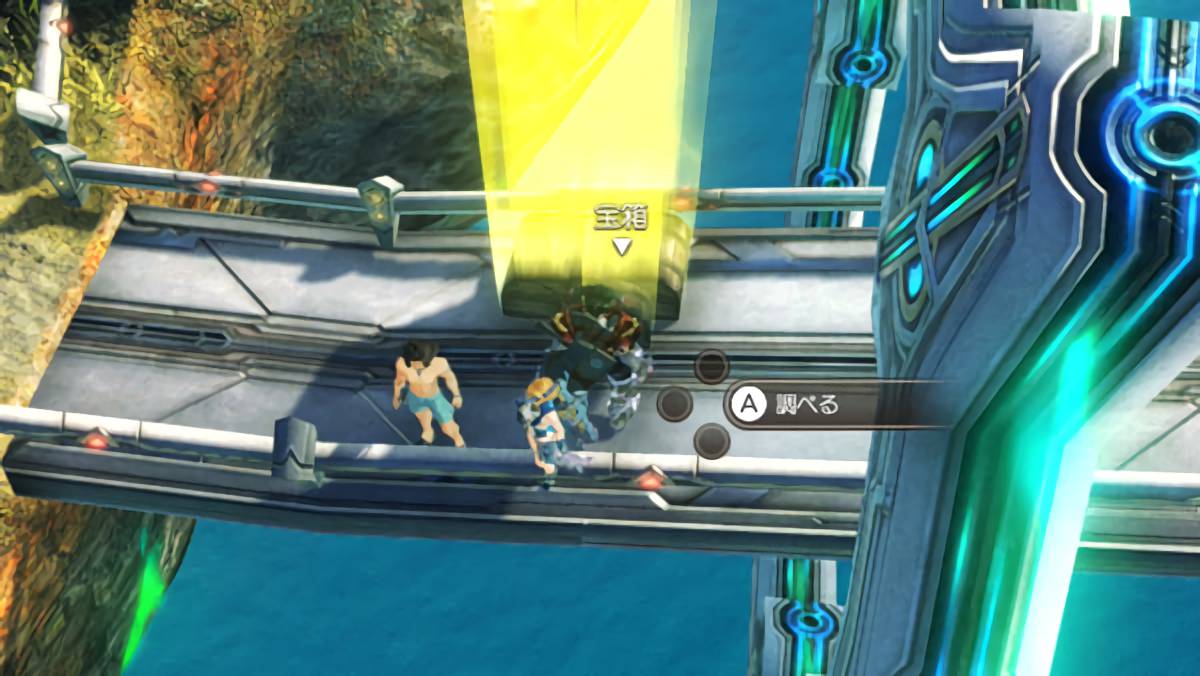
今回も「ゼノブレイドDE」のドロップ率検証を例にして紹介します。
マクロの記録

読み取る文字が表示されているタイミングで「CAPTURE」ボタンを入力。
それだけです。最適な入力はゲームや調べる内容によって異なるので各自で考える。
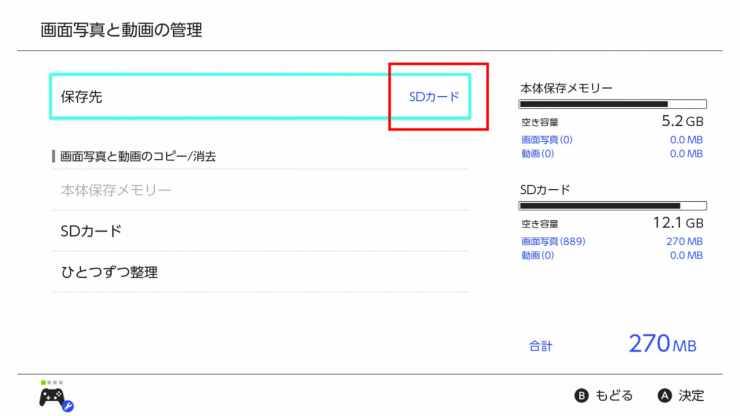
画像はSDに保存されるようにセットしておきます。
設定 > データ管理 > 画面写真と動画の管理

ゼノブレイドDEのドロップ率は「宝箱を開けたときに抽選」「セーブロードで再抽選可能」なのでこんな感じに宝箱を大量に集めてセーブすると効率が良いです。

マクロは放置で永久ループ可能ですが、一定回数で停止するような機能はありません。
1ループの長さを測って時間が来たら自分で止めましょう。
あとはループ開始前の写真の保存数もメモしておくと良いでしょう。
XnConvertで必要部分だけ切り抜く
まずはSDからPCにキャプチャした画像を移します。Nintendo > Album以下のフォルダに入っていると思います。
切り抜きは「XnConvert」を使います。
- 複数一括操作で画像を拡大・縮小・変換できる
- ポータブルソフトでインストール不要
の2点で選びました。切り抜けるならコマンドでも何でもいいです。
公式サイト:https://www.xnview.com/en/xnconvert/
から環境にあったZip版をダウンロードして展開します。インストーラーでもいいならSetup版を。
展開したフォルダにある「xnconvert.exe」を起動。

起動したらまずは変換するファイルを選びます。個別に選択したり、フォルダごとドロップしてもいけます。この一覧にあるファイル全てに変換が適用されます。
変換元のファイルは残ります。
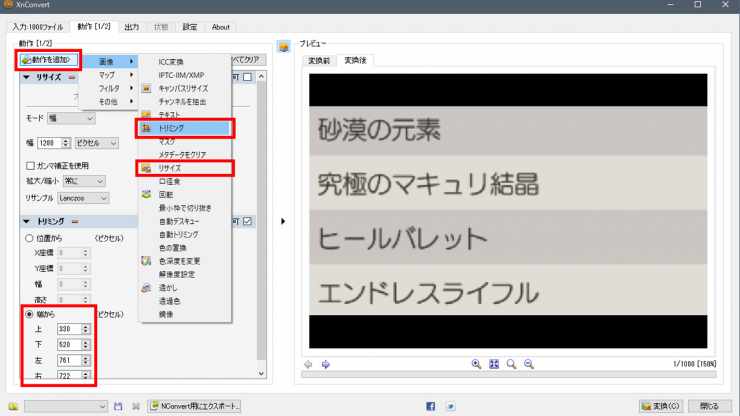
隣の「動作」タブを選んで「リサイズ」と「トリミング」を設定します。
「動作を追加」から選んでパラメータを調整します。変更後のプレビューが右に表示されるので見ながら調整できます。
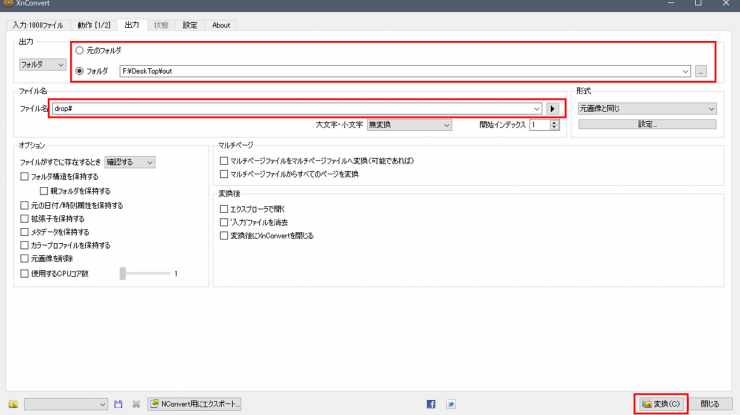
最後に「出力」タブで出力する場所を指定します。
専用のフォルダを作ってそれを選択すると良いでしょう。
名前は入力規則が色々とあります。
「#」でインデックスが付与されるので「drop#」みたいにしておけばdrop1.jpg、drop2.jpg、drop3.jpgという感じで生成されます。
最後に右下の変換を押せば終わりです。
Tesseract-OCRで文字を読み取ってテキストファイルに出力
インストール
まずはTesseractをダウンロードしてインストールします。
配布場所:https://github.com/UB-Mannheim/tesseract/wiki

現在の最新版はv5.0.0-aです。今後もアップデートされて配布場所が変わったりすると思いますがその場合は各自で調べてください。
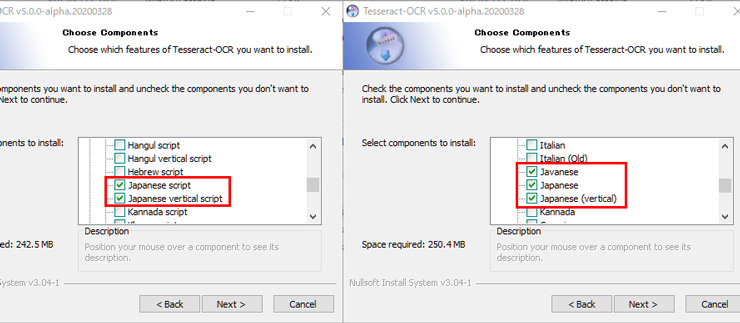
インストールするときは「Japanese」と名がついたスクリプトと言語データにチェックを付けておきます。チェック項目は全部で5つですね。
バッチファイルの作成
Tesseractの基本的な使い方は調べれば出てきますがコマンドから
「tesseract.exe 対象画像 出力ファイル名 -l jpn」で使います。
通常は対象画像に画像のパスを指定しますが、複数ファイルを処理する場合は画像のパスが書かれたテキストファイルを指定します。
今回は対象が多いので画像をドロップするだけで済むバッチファイルを作ります。
以下のコマンドを貼り付けたテキストファイルを「gen.bat」として保存してください。
@echo off
set savedir=%~dp0
cd /d %savedir%
dir /B /S *.jpg > list.txtrem tesseract_pathにtesseract.exeのパスを代入
set tesseract_path=”C:\Program Files\Tesseract-OCR\tesseract.exe”rem ファイル一覧のリストと出力、このout.txtが文字解析の結果
set list=%~dp0%list.txt
set out=%~dp0%outrem 実行コマンド、c- page_separator=”区切り文字”
set lst=%tesseract_path% -c page_separator=”[sep]” %list% %out% -l jpn%lst%
pause
「tesseract.exe」のパスだけは環境に依存するので調整してください。
バッチファイルができたら切り抜いた画像がある場所に配置します。

あとは「gen.bat」をダブルクリックするだけです。
ドロップしたファイルの一覧が「list.txt」に、読み取った結果が「out.txt」に出力されます。あとは煮るなり焼くなりお好きにどうぞ。
out.txtの整形
画像ごとの区切りは[sep]としているので
***
[sep]***
[sep]***
***
[sep]***
みたいな内容になっていると思います。
これもバッチファイルでcsvに出力できたりするんですが、私はDOSコマンドについて詳しくないのでお手上げです。
代わりにCSVに変換するプログラムをjsで作っておきました。
↑ここに出力された「out.txt」を渡せばCSV形式の「out.csv」になります。
選択したファイルはオフラインのブラウザ上で処理されます。アップロードしないので安心を。区切り文字は[sep]しか対応していません。
ということで以上です。これでキャプチャボタンの入力に対応しているマクロコンがあればプログラミングの知識がなくても検証できるようになったと思います。
今回もニッチな情報でしたが検証した内容は多くのプレイヤーの役に立つ(こともある)ので調べプレイが好きな方に届けば。












なんか、このまま行くと乱数調整みたいな感じでドロップ吟味めっちゃ効率良く出来そうな気がしますけど…ドロップ集計すると何かメリットとかありますか?